Algorithmes utilisés pour le traitement des données en FTIR
Dans cet article, je présenterai certains des algorithmes utilisés pour une variété d'opérations de traitement des données appliquées aux spectres en FTIR. Ces algorithmes sont adoptés dans le logiciel IRsolution.
Lissage
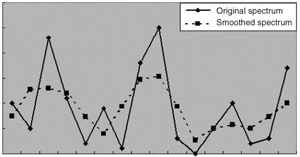
Fig. 1 Lissage Simple Basé sur le Remplacement par des Valeurs Moyennes
Le lissage est un processus utilisé pour lisser la forme des spectres.
Par exemple, appliquer ce processus à un spectre avec un faible rapport signal/bruit permet de réduire l'influence du bruit.
Bien que la résolution des pics diminue, l'existence des pics devient plus facile à déterminer et la forme générale du spectre devient plus claire. Ainsi, dans l'analyse d'échantillons inconnus, ce processus est efficace pour obtenir des informations qualitatives.
Le lissage d'un spectre consiste à réduire le degré auquel l'intensité spectrale change à des points de données individuels. Une manière très simple de lisser serait de remplacer la valeur d'intensité de chaque point de données individuel par la valeur obtenue en moyennant les intensités de trois points, qui consistent en le point de données lui-même et deux points voisins. Cela permet, dans une certaine mesure, d'obtenir l'effet souhaité. Dans la figure ci-dessous, le graphique en ligne pointillée représente le résultat de l'application de ce processus au graphique en ligne continue. Le degré auquel le spectre change à chaque point est réduit.
IRsolution utilise un algorithme légèrement plus complexe. Au lieu de prendre la moyenne de trois points, il utilise la valeur obtenue en multipliant l'intensité de chacun des points de lissage spécifiés par un facteur de pondération et en totalisant les valeurs ainsi obtenues. Ce processus est appelé l'application d'un "filtre de lissage Savitzky-Golay de troisième ordre" et les facteurs sont déterminés par une fonction qui est
maximale au point de données d'origine et diminue à mesure que l'on s'éloigne de ce point. Le nombre de points de lissage peut être spécifié dans la fenêtre de commande de lissage d'IRsolution. Si cette valeur est définie sur une grande valeur, la moyenne pondérée pour les points de données couvrant une large gamme est obtenue et, en général, un spectre plus lisse, avec relativement peu de bosses, est produit.
Interpolation
L'interpolation est un processus permettant d'obtenir des intensités spectrales à des emplacements sans points de données d'origine à partir des intensités spectrales des points de données environnants. Elle augmente le nombre de points de données.
Ce processus est utilisé, par exemple, lors de la comparaison de deux ensembles de données ayant des points de données à des intervalles différents parce que les données d'origine ont été obtenues avec des résolutions différentes. En appliquant la forme appropriée d'interpolation, les tailles des intervalles entre les points de données peuvent être unifiées.
Il existe un type simple d'algorithme d'interpolation dans lequel deux points sont reliés par une ligne droite et un nouveau point est créé sur cette ligne. IRsolution, cependant, utilise un algorithme basé sur la formule de Laplace-Everett. Il s'agit d'un algorithme d'interpolation qui crée de nouveaux points en utilisant les intensités de plusieurs points environnants, pas seulement les points voisins, et reflète ainsi les tendances des courbes sur une gamme relativement large. Avec IRsolution, quatre points environnants sont utilisés.
À titre d'exemple, supposons qu'il y ait quatre points, P0, P1, P2 et P3 (dans l'ordre), sur une courbe spectrale et que leurs intensités soient respectivement I0, I1, I2 et I3. Si P est un point qui divise P1 et P2 en interne dans le rapport t:1-t, l'intensité à P obtenue par interpolation simple est la suivante :
Cependant, l'intensité obtenue avec l'algorithme IRsolution est la suivante :
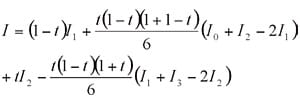
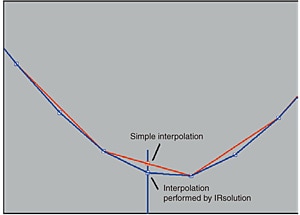
Fig. 2 Interpolation Basée sur la Formule de Laplace-Everett
La fonction d'interpolation d'IRsolution permet non seulement de réduire la taille des intervalles de données par un facteur spécifié (par exemple, à des intervalles de moitié ou de quart de la taille), mais permet également de passer à des intervalles de données de toute taille spécifiée. Cela est possible parce que la fonction obtient une courbe en utilisant les points de données d'origine et crée de nouveaux points de données en obtenant les intensités aux nouveaux intervalles de données spécifiés. Pour cette raison, même si l'intervalle de données d'origine est un multiple du nouvel intervalle de données spécifié, et que les nombres d'ondes des anciennes et nouvelles données coïncident, les intensités respectives seront, en général, légèrement différentes.
Il faut se rappeler que l'interpolation n'est qu'une méthode mathématique pour estimer les valeurs d'intensité et que les valeurs obtenues peuvent différer des intensités réelles.
Détection des Pics
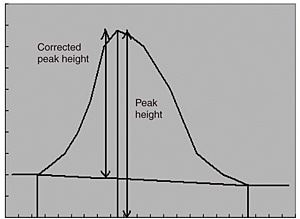
Fig. 3 Hauteur du Pic et Hauteur du Pic Corrigée
La détection des pics implique l'identification de l'absorbance à des nombres d'ondes spécifiques dans un spectre, et est utilisée pour l'analyse qualitative et quantitative des substances échantillons.
Avec IRsolution, la valeur seuil, le niveau de bruit et la surface minimale sont nécessaires comme paramètres pour la détection des pics. (Bien que ces valeurs diffèrent selon que l'axe vertical du spectre représente la transmittance ou l'absorbance, le principe de base est le même. Ici, un exemple où l'axe vertical représente l'absorbance est utilisé.)
Tout d'abord, les dérivées de premier et de second ordre du spectre sont calculées et le résultat est enregistré. Ensuite, en utilisant ces résultats, les positions des nombres d'ondes sur le spectre où la dérivée de premier ordre passe d'une valeur positive à une valeur négative sont détectées, et celles-ci sont considérées comme des candidats de pic (car il est possible qu'elles soient des positions où le spectre prend des valeurs maximales).
Parmi ces candidats de pic, ceux pour lesquels l'absorbance n'atteint pas la valeur seuil sont
écartés. Ensuite, la différence de valeur de la dérivée de premier ordre entre chaque point candidat et les points avant et après est calculée, et les points pour lesquels la valeur absolue de cette différence n'atteint pas le niveau de bruit spécifié sont jugés comme étant du bruit et sont écartés.
Parmi les points avant et après les candidats de pic restants, on recherche des points pour lesquels la dérivée de premier ordre passe d'une valeur négative à une valeur positive et pour lesquels la dérivée de second ordre est négative. Si de tels points sont trouvés, ils sont jugés être les "vallées" avant et après les pics. Si les vallées ne sont pas trouvées, les candidats correspondants sont jugés ne pas être des pics et sont écartés. Les vallées trouvées avant et après les points candidats de pic sont reliées pour former des lignes de base, et les hauteurs et les surfaces des pics corrigés sont calculées. Si ces deux valeurs sont supérieures à la valeur seuil spécifiée et à la surface minimale respectivement, les points correspondants sont jugés être des pics.
Les opérations sont essentiellement les mêmes dans le cas où l'axe vertical représente la transmittance. Les valeurs de transmittance aux creux des pics (plutôt qu'aux sommets des pics), les profondeurs de ces creux par rapport à la ligne de base et les surfaces délimitées par les pics et la ligne de 100 % et par les pics et la ligne de base sont utilisées à la place.
Calcul de l'Épaisseur du Film
Cette fonction calcule, à partir du nombre de franges d'interférence dans une plage de nombres d'ondes spécifiée, l'épaisseur d'un film à travers lequel la lumière infrarouge passe. En termes d'algorithmes, cette fonction peut être considérée comme une détection de pic simple et son application.
Comme pour la détection de pic standard, la dérivée de premier ordre du spectre est calculée, et les endroits où sa valeur passe de positive à négative sont détectés. Des vérifications précises du niveau de bruit ne sont pas effectuées sur le spectre. De telles caractéristiques sont considérées comme des pics.
Les nombres d'ondes des pics maximaux et minimaux dans la plage de nombres d'ondes spécifiée sont détectés, et le nombre de pics entre eux est compté. Un calcul basé sur la formule suivante est effectué sur le nombre de pics comptés et l'indice de réfraction et l'angle d'incidence définis.
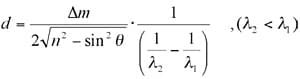
Ici, "d" représente l'épaisseur du film, "λ1" et "λ2" représentent les longueurs d'onde des pics ou des vallées à chaque extrémité de la plage de nombres d'ondes spécifiée, "n" représente l'indice de réfraction du film, "θ" représente l'angle d'incidence de la lumière infrarouge par rapport à l'échantillon, et "Δm" représente le nombre de pics entre "λ1" et "λ2".
Correction Atmosphérique
Il s'agit d'une fonction corrective qui soustrait la composante d'un spectre correspondant à l'absorbance due à la vapeur d'eau et au dioxyde de carbone dans l'atmosphère, et supprime ainsi l'influence de ces facteurs. Avec IRsolution, la forme approximative du spectre de fond affiché au format spectre de puissance est calculée, et en utilisant cela et les pics d'absorption dans le spectre de fond d'origine, les pics de vapeur d'eau et de dioxyde de carbone sont annulés.
Tout d'abord, la forme approximative du spectre de fond est calculée. Pour ce faire, les chiffres entrés pour la vapeur d'eau et le dioxyde de carbone dans les plages de nombres d'ondes élevés et faibles via la fenêtre de réglage des paramètres sont utilisés. Ces chiffres sont des facteurs d'échelle exprimés en nombres d'ondes qui sont utilisés pour effectuer une granulation grossière du spectre. Dans les régions de nombres d'ondes respectives, les changements dans les petites plages de nombres d'ondes ne dépassant pas les chiffres définis sont ignorés, et un spectre de contour sans pics d'absorption fins est calculé.
Les plages de nombres d'ondes sont les suivantes :
Plage de nombres d'ondes élevés pour la vapeur d'eau :
3,540 à 3,960 cm-1
Plage de nombres d'ondes faibles pour la vapeur d'eau :
1,300 à 2,000 cm-1
Plage de nombres d'ondes élevés pour le dioxyde de carbone :
2,250 à 2,400 cm-1
Plage de nombres d'ondes faibles pour le dioxyde de carbone :
600 à 740 cm-1
Le spectre résultant a la forme d'une courbe enveloppe créée en supprimant les petites bosses du spectre de fond d'origine. À partir de la différence entre ces spectres, un modèle de pic d'absorption pour la vapeur d'eau et le dioxyde de carbone dans l'atmosphère est calculé.
De plus, en ce qui concerne les spectres d'échantillons affichés au format spectres de puissance, le même type de modèle de pic est calculé, et le rapport du spectre de fond à ce modèle de pic est obtenu. Soustraire le modèle de pic obtenu en effectuant une mise à l'échelle avec ce facteur du spectre de puissance permet d'obtenir un spectre à partir duquel l'influence de la vapeur d'eau et du dioxyde de carbone dans l'atmosphère est éliminée. (Le spectre final est donné sous forme de ratio des spectres d'échantillon et de fond.)
La fonction de correction atmosphérique d'IRsolution effectue donc la correction en utilisant des spectres de puissance pour le fond et l'échantillon. Pour cette raison, la correction n'est possible que pour les spectres obtenus avec IRsolution qui sont dans un format portant l'extension .smf.
Recherches dans les Bibliothèques
Fig. 4 Sélection de l'Algorithme de Recherche
Beaucoup des algorithmes utilisés pour les recherches dans les bibliothèques sont extrêmement complexes. Il serait impossible de donner une explication exhaustive de tous dans un espace aussi limité. Ici, je vais donc décrire un type relativement simple d'algorithme dans le contexte du fonctionnement d'une recherche typique dans une bibliothèque.
La fonction de recherche du logiciel IRsolution de Shimadzu prend en charge de nombreux types de techniques de recherche. La plus basique est appelée "recherche de spectre". Lors de l'utilisation de la recherche de spectre, divers paramètres doivent être définis, y compris la sélection de l'algorithme.
Différents algorithmes peuvent être sélectionnés dans la recherche de spectre d'IRsolution. Parmi ceux-ci, l'algorithme "Différence" est relativement simple et je vais décrire l'opération effectuée lorsque cet algorithme est utilisé.
Lorsqu'une recherche de spectre est exécutée avec IRsolution, le traitement de la plage de nombres d'ondes est effectué en premier. Il s'agit d'une fonction de sélection par laquelle le spectre de l'échantillon est comparé aux spectres de la bibliothèque dans une plage de nombres d'ondes spécifiée, plutôt que dans la plage de tout le spectre. Cette fonction permet d'effectuer des recherches en utilisant uniquement des parties caractéristiques des spectres. En fait, cette fonction convertit la plage de nombres d'ondes exprimée en unités cm-1 en un indice (nombre) des points de données qui configurent le spectre, et seuls les points de données de l'indice applicable sont transférés à la partie fonction de comparaison du logiciel.
Ensuite, le spectre est normalisé en termes d'intensité. Ce processus correspond à la commande "Normaliser" qui est affichée dans le menu "Manipulation" d'IRsolution. Un facteur constant est appliqué à l'ensemble du spectre de sorte que l'absorbance maximale devienne 1 tout en préservant la forme du spectre.
En général, les tailles des spectres des échantillons inconnus diffèrent de celles des spectres de la bibliothèque ; par conséquent, ce traitement est nécessaire pour faciliter la comparaison basée sur des formes spectrales appropriées.
Après que la taille du spectre a été normalisée pour tous les points de données dans la plage de nombres d'ondes définie, les différences d'intensité entre le spectre de l'échantillon inconnu et les spectres de la bibliothèque sont obtenues sous forme de valeurs absolues, et ces valeurs sont totalisées. Si le spectre de l'échantillon inconnu et un spectre de la bibliothèque sont une correspondance parfaite, cette valeur sera naturellement zéro. En pratique, la valeur varie en fonction du degré de similarité entre les deux spectres. Multiplier cette valeur par un certain facteur et la soustraire de 1 000 donne un indice (la "qualité de correspondance") qui sera égal à 1 000 dans le cas d'une correspondance parfaite. Cette opération est effectuée sur tous les spectres de la bibliothèque utilisés, et les résultats sont affichés sous forme de liste avec les spectres classés par ordre décroissant de qualité de correspondance.
Le fonctionnement d'autres types d'algorithmes est essentiellement le même. La seule différence peut être, par exemple, qu'au lieu des valeurs absolues des différences entre le spectre de l'échantillon inconnu et les spectres de la bibliothèque, les carrés des différences sont utilisés.
Résumé
Ici, j'ai donné une explication simple des algorithmes utilisés dans certaines des opérations de traitement de données effectuées par IRsolution. Dans l'utilisation des fonctions de traitement de données, je ne pense pas qu'il soit généralement nécessaire d'être conscient des détails précis de l'opération. Comprendre les algorithmes, cependant, peut aider l'utilisateur à apprécier les effets des processus correspondants. Parfois, lors de l'utilisation d'une opération de traitement de données, essayez de prendre conscience de l'utilité de l'opération.



